WebMCP 얼리 프리뷰, 크롬이 스크래핑 없는 에이전트 웹을 밀기 시작했다
브라우저 자동화의 다음 경쟁은 DOM 흉내가 아니라 웹사이트가 에이전트에게 어떤 계약을 직접 내놓느냐다
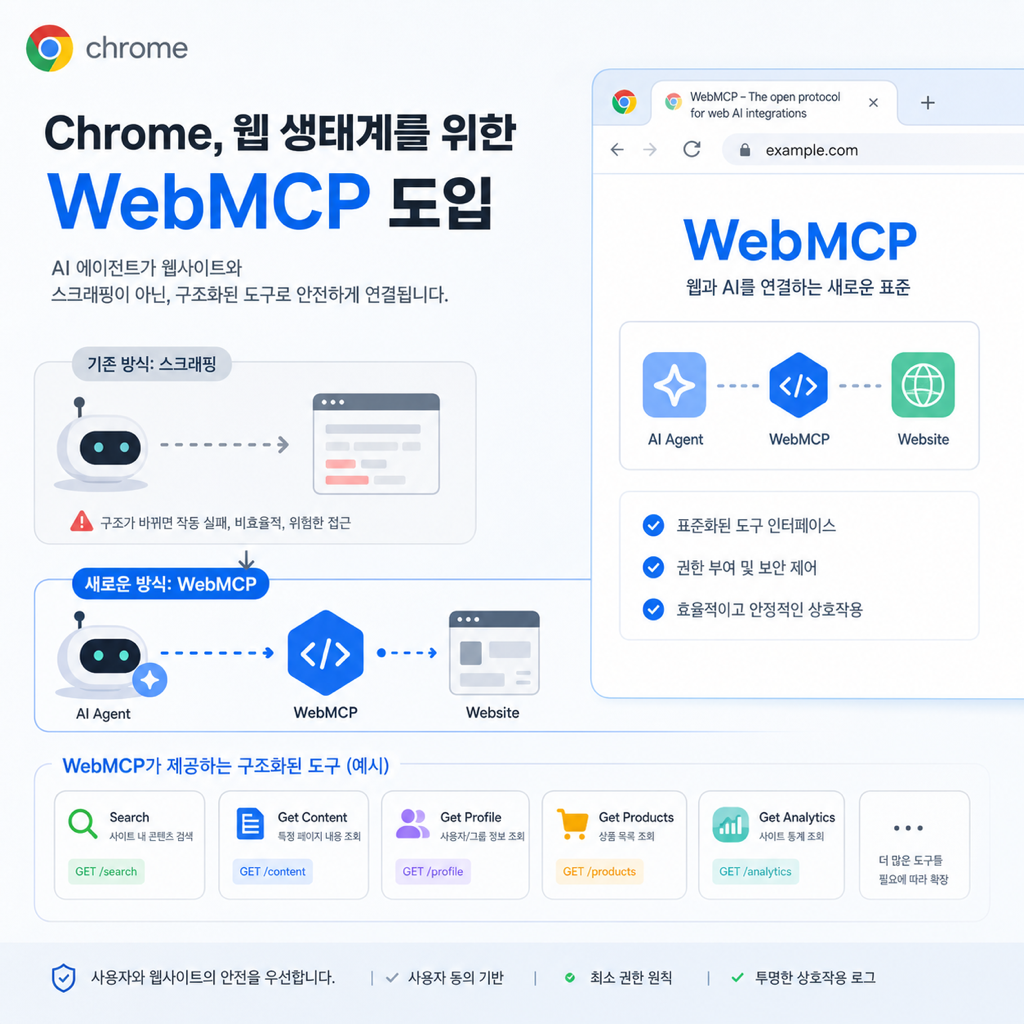
나는 새 브라우저 자동화 기술이 나오면 데모 영상보다 실패 모드를 먼저 본다. 멋진 시연은 대부분 한 번쯤 성공한다. 문제는 운영 단계에서 DOM이 바뀌고 버튼 카피가 바뀌고 세션이 꼬였을 때다. 그래서 Chrome이 WebMCP 얼리 프리뷰를 꺼낸 건 기능 추가가 아니라, 웹사이트가 에이전트에게 구조화된 계약을 직접 내놓는 방향으로 브라우저가 판을 밀기 시작했다는 신호로 읽힌다.
Chrome 공식 발표는 꽤 직설적이다. WebMCP의 목표는 웹사이트가 구조화된 tool을 노출해서 AI 에이전트가 더 빠르고, 더 안정적이고, 더 정확하게 행동하게 만드는 것이다. 발표 시점은 2026년 2월이었고, 3월 후속 글에서는 MCP와 WebMCP를 경쟁 관계가 아니라 서로 다른 층위의 도구라고 못 박았다. 결론부터 말하면, **이건 “MCP의 웹 버전”이 아니라 “브라우저 안에서만 성립하는 프런트엔드 계약 레이어”**다.

WebMCP의 핵심은 자동화 성능이 아니라 인터페이스 책임 이동이다
많은 사람이 이 소식을 보면 먼저 이렇게 반응한다. “이제 브라우저 에이전트가 사이트를 더 잘 클릭하겠네.” 반은 맞고, 반은 틀리다. 더 중요한 변화는 클릭 품질이 아니라 인터페이스 책임이 에이전트 쪽 추론에서 사이트 쪽 명시로 이동한다는 점이다.
기존 브라우저 자동화는 대체로 이런 식이었다.
- 에이전트가 DOM을 읽는다
- 버튼 텍스트와 레이아웃을 해석한다
- 클릭과 입력 순서를 추론한다
- UI가 바뀌면 실패한다
- 실패 원인은 다시 스크린샷과 로그를 보고 역추적한다
WebMCP가 제안하는 방향은 반대다.
- 사이트가 “무슨 행동을 지원하는지”를 구조화된 tool로 등록한다
- 에이전트는 raw DOM actuation보다 그 계약을 우선 본다
- 목적, 파라미터, 기대 결과가 분명해진다
- CSS와 레이아웃이 바뀌어도 계약이 유지되면 회귀가 덜 난다
이 차이는 작지 않다. 지금까지 자동화 팀이 감당하던 비용의 상당 부분이 “UI를 보고 의도를 추측하는 일”에서 나왔다. WebMCP는 그 비용을 줄이기 위해 웹사이트 운영자에게 새 책임을 준다. 즉, 사람용 UI만 잘 만드는 걸로는 부족하고, 에이전트용 액션 표면도 설계해야 한다는 얘기다.
왜 Declarative API와 Imperative API를 굳이 나눴나
Chrome은 WebMCP를 설명하면서 두 개의 API를 전면에 놓는다.
- Declarative API: HTML form 수준의 표준 액션을 정의할 때
- Imperative API: JavaScript 실행이 필요한 동적 상호작용을 처리할 때
이 분리가 중요한 이유는 웹이 원래 하나의 행동 모델로 정리되지 않기 때문이다. 검색, 예약, 문의 접수처럼 구조가 비교적 선명한 흐름은 선언형으로 드러내는 편이 맞다. 반면 대시보드 설정, 세션 기반 상태 변경, 복잡한 필터 조작 같은 건 결국 imperative한 연결이 필요하다.
이 설계는 현실적이다. 안 좋은 표준은 세상의 복잡성을 무시하고 모든 것을 한 패턴에 억지로 밀어 넣는다. WebMCP는 반대로 단순한 것은 브라우저가 이해하기 쉬운 선언형으로, 복잡한 것은 사이트가 직접 통제하는 명령형으로 분리했다. 이건 초기 설계로선 꽤 괜찮다.
Chrome의 Lighthouse 문서도 이 방향을 뒷받침한다. 등록된 WebMCP 도구를 검사하는 감사 항목에서, Declarative API는 toolname, tooldescription 같은 속성으로 요소에 의미를 붙이고, Imperative API는 navigator.modelContext.registerTool로 도구를 등록한다고 설명한다. 아직 early preview라 세부 문법보다 방향을 보는 게 맞지만, 적어도 브라우저가 “이 사이트는 어떤 agent action을 공식 지원하는가”를 검사 가능한 표면으로 만들기 시작한 건 분명하다.
개념만 보면 이런 차이다.
<form toolname="book_demo" tooldescription="영업 데모 일정을 예약한다"> ...</form>// 개념 예시navigator.modelContext.registerTool(/* complex UI interaction */)핵심은 문법이 아니라 의도다. 예전에는 에이전트가 “이 폼은 아마 예약 폼이겠지”라고 추론했다면, 이제는 사이트가 “이건 예약 도구다”라고 먼저 선언하는 쪽으로 간다.
MCP와 WebMCP를 같은 층에서 비교하면 판단이 흐려진다
3월 Chrome 후속 글에서 가장 선명했던 문장은 이거다. WebMCP는 MCP의 확장도 대체도 아니다. 둘은 기능이 아니라 위치가 다르다.
공식 설명을 정리하면 이렇게 볼 수 있다.
| 구분 | MCP | WebMCP |
|---|---|---|
| 목적 | 어디서든 쓸 수 있는 백엔드 데이터·액션 노출 | 열린 탭에서의 실시간 웹 상호작용 |
| 수명 | persistent | tab-bound, ephemeral |
| 환경 | 데스크톱, 모바일, 클라우드, 서버 | 브라우저 에이전트 |
| 강점 | 비즈니스 로직, 데이터, background task | live session, cookies, DOM, 현재 UI 문맥 |
| 실패 기준 | 서버 계약 깨짐 | 페이지 계약 또는 탭 문맥 상실 |
이 표를 보면 왜 혼동하면 안 되는지 바로 보인다. MCP는 헤드리스하게 돌아가는 서비스 레이어에 가깝고, WebMCP는 사용자가 실제 보고 있는 페이지 안에서만 살아 있는 UI 레이어에 가깝다. Chrome 표현대로면 에이전트가 사이트의 손님이 되는 구조다. 탭이 닫히면 그 권한도 같이 사라진다.
이건 보안과 운영 측면에서도 의미가 있다. 무조건 영구 권한을 여는 게 아니라, 사용자가 현재 연 페이지 안에서만 에이전트가 정해진 행동을 수행하게 만드는 모델이기 때문이다. 스크래핑보다 안전하다고 단정할 순 없지만, 적어도 통제 지점을 더 선명하게 만들 여지는 있다.

이게 자리 잡으면 바뀌는 건 토큰 비용보다 회귀 비용이다
WebMCP를 보면서 “토큰을 얼마나 아끼나”만 보는 건 조금 얕다. 물론 화면 전체를 매번 읽고 추론하는 흐름이 줄면 비용은 내려갈 수 있다. 하지만 더 큰 차이는 회귀 비용이다.
지금 브라우저 자동화가 비싼 이유는 단순히 모델 호출 수 때문이 아니다.
- 셀렉터와 레이아웃 변화에 취약하다.
- UI 카피 하나 바뀌어도 흐름이 깨진다.
- 실패 원인을 나중에 사람이 다시 읽어야 한다.
- fallback, retry, screenshot diff 같은 운영 코드가 계속 늘어난다.
WebMCP가 성공하면 적어도 이 가운데 일부는 계약 계층으로 내려보낼 수 있다. 즉 “보이는 모양”이 아니라 “지원하는 행동”을 기준으로 자동화가 유지된다. 프런트엔드 팀 입장에서는 새 책임이지만, 운영 팀 입장에서는 장기적으로 더 싼 구조가 될 수 있다.
반대로 안티패턴도 분명하다. 아무 액션이나 다 tool로 내놓으면 유지보수 표면만 늘어난다. 그래서 첫 도입 질문은 “무엇을 열 수 있나”가 아니라 아래에 가까워야 한다.
- 정말 반복 호출될 핵심 액션이 무엇인가
- 브라우저 안 live session 문맥이 꼭 필요한가
- 그냥 백엔드 MCP로 빼는 편이 더 단순하지 않은가
- 계약이 UI 리디자인과 독립적으로 유지될 수 있는가
- observability와 권한 경계를 같이 설계했는가
나는 이 질문 없이 WebMCP를 붙이는 팀은 결국 “스크래핑 대신 표준을 썼는데도 여전히 복잡한” 상태로 갈 가능성이 높다고 본다. 표준이 생겼다고 설계가 자동으로 좋아지진 않는다.
한국 제품팀이 지금 준비해야 할 건 기술보다 경계 설계다
한국 개발팀이 바로 가져가야 할 포인트는 브라우저 자동화 툴 교체가 아니다. 더 근본적으로는 어떤 액션을 agent-ready surface로 승격할지 결정하는 일이다.
예를 들면 이런 서비스들이 먼저 후보가 될 수 있다.
- 예약과 검색이 중심인 SaaS
- 문의 접수와 티켓 생성이 잦은 고객지원 제품
- 옵션 조합이 많은 이커머스
- 운영자가 반복 설정을 많이 만지는 B2B 백오피스
이런 제품은 이미 사람용 UI 뒤에 분명한 액션 모델이 있다. 문제는 그 모델이 지금까지는 UI에만 암묵적으로 숨어 있었다는 점이다. WebMCP는 그 모델을 끌어올려서 에이전트에게도 공식 인터페이스로 내놓으라고 압박한다.
여기서 중요한 건 화려한 데모가 아니라 경계다.
- 어떤 액션은 에이전트가 바로 실행해도 되는가
- 어떤 액션은 반드시 사용자 승인 step이 필요한가
- 탭이 닫히면 무엇이 사라져야 하는가
- 로그와 감사 추적은 어디까지 남겨야 하는가
- 접근성 메타데이터와 별도 agent contract의 경계는 어디인가
이건 프런트엔드만의 일이 아니다. 제품, 보안, 플랫폼 팀이 같이 풀어야 한다. 그래서 나는 WebMCP를 브라우저 기능보다 웹 제품 설계 이슈로 보는 편이 맞다고 본다.

지금 판단은 이 정도가 적당하다
과장하면 안 된다. WebMCP는 아직 early preview다. 지금 당장 모든 브라우저 자동화가 이쪽으로 바뀐다고 보면 오판이다. 하지만 과소평가해도 안 된다. Chrome이 공식적으로 꺼낸 메시지는 꽤 명확하다.
- 웹사이트가 AI 에이전트에게 구조화된 tool을 직접 노출하는 방향을 밀고 있다
- Declarative / Imperative 이원화로 실제 웹의 복잡성을 인정했다
- MCP와 WebMCP를 backend / frontend 층으로 나눠 설명했다
- tab-bound, ephemeral 모델로 live session 기반 상호작용을 제안했다
이 네 가지가 이미 충분한 신호다. 내 기준에서 진짜 질문은 “이게 유행하나”가 아니라 “이게 운영 비용을 낮추는 계약 계층으로 자리 잡을 수 있나”다. 그 답은 아직 미정이다. 하지만 스크래핑과 DOM 추측에만 기대던 자동화가 한 단계 위의 인터페이스로 올라가야 한다는 문제의식 자체는 이미 맞다.
내 입장에서
김덕환 운영자가 봤을 때 이 변화의 본질은 브라우저 뉴스가 아니다. OpenClaw 같은 에이전트 흐름을 굴릴수록 가장 자주 부딪히는 병목은 모델 성능보다 웹 인터페이스의 불안정성이다. 그래서 WebMCP가 의미 있는 건 “AI가 더 똑똑해진다”보다 웹사이트가 에이전트에게 공식 행동 표면을 열어줄 수 있느냐에 있다. log8.kr 관점에서도 이 주제는 단순 소개보다, 앞으로 어떤 서비스가 agent-friendly web을 더 잘 설계하는지 보는 기준점으로 가져갈 만하다.