Claude Code Routines, 프롬프트를 반복 실행 가능한 개발 워크플로우로 바꾸는 전환점
AI 코딩의 경쟁축이 모델 답변에서 실행층과 루틴 자산으로 이동하고 있다
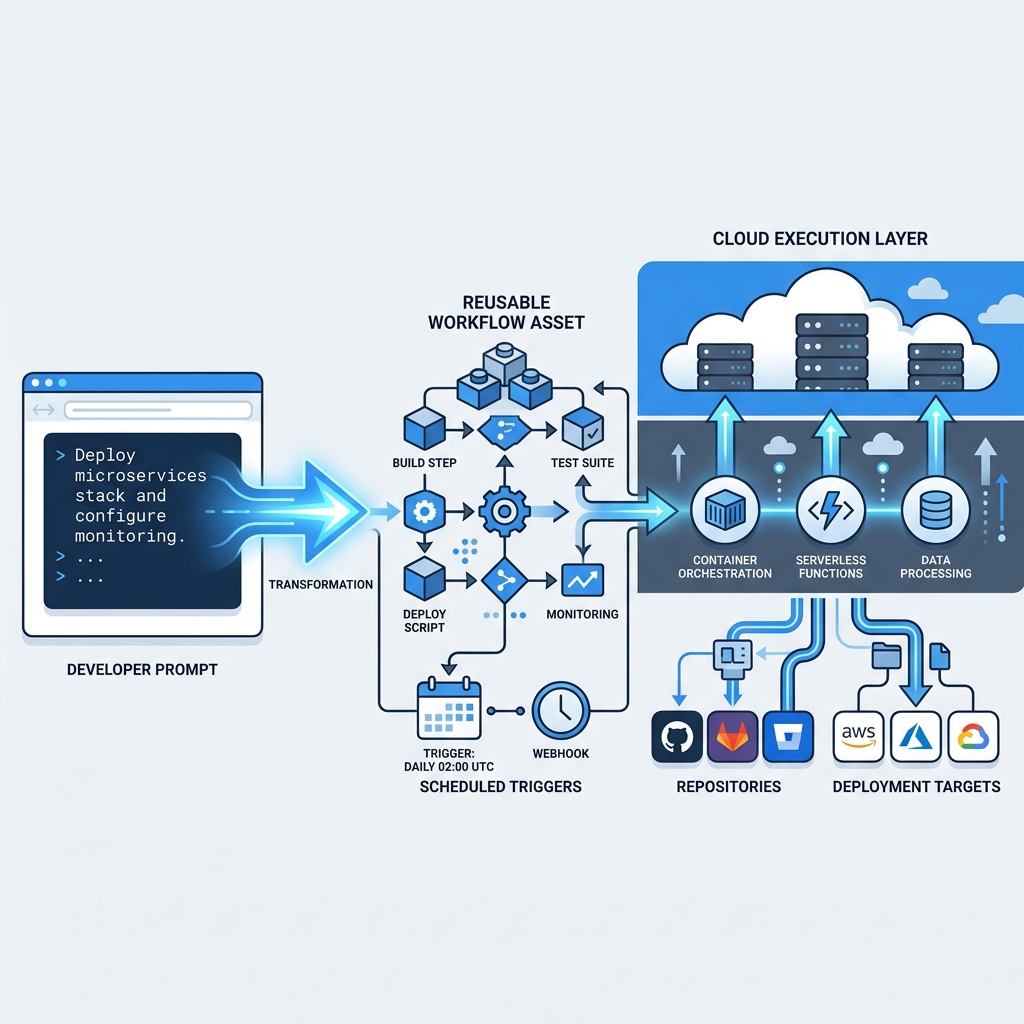
이번 화제의 본질은 모델이 더 똑똑해졌다는 얘기가 아니다. 프롬프트가 일회성 입력창을 벗어나, 반복 실행 가능한 작업 자산으로 승격되고 있다는 점이다.
Claude Code Routines가 던진 신호는 꽤 선명하다. 이제 AI 코딩 툴의 경쟁은 “한 번 잘 답하는가”보다, 반복 업무를 누구의 실행층 위에서 얼마나 안정적으로 자동화할 수 있는가로 이동하고 있다. 프롬프트 엔지니어링이 워크플로우 엔지니어링으로 넘어가는 순간이라고 보는 편이 정확하다.
Anthropic 설명을 종합하면 Routines는 단순 저장 프롬프트가 아니다. 프롬프트, 하나 이상의 리포지토리, 커넥터를 묶어 저장한 뒤 스케줄이나 트리거에 따라 Anthropic 관리형 인프라에서 자동 실행하는 구조다. 여기서 중요한 건 “반복 실행”보다도 클라우드 실행층이다. 맥북이 닫혀 있어도 돌아가고, 로컬에서 cron과 툴링을 직접 붙이지 않아도 된다는 점이 게임을 바꾼다.
Claude Code Routines가 실제로 바꾼 것
이 기능을 단순 자동화라고 보면 반만 본 거다. 실은 세 가지 변화가 한 번에 들어왔다.
첫째, 프롬프트가 저장된 실행 구성으로 바뀌었다. 이전에는 좋은 프롬프트가 있어도 메모장이나 노션에 붙여두고 다시 실행해야 했다. 이제는 같은 의도를 prompt + repo + connector 조합으로 고정한 뒤 반복 호출할 수 있다.
둘째, 실행 위치가 로컬 노트북 밖으로 이동했다. 9to5Mac 보도대로 Routines는 Anthropic 웹 인프라에서 실행되기 때문에 로컬 기기가 꺼져 있어도 작업이 돈다. 이건 생산성 기능처럼 보이지만, 실제로는 경량 운영 자동화에 더 가깝다.
셋째, 트리거가 스케줄을 넘어선다. The Register 정리대로 이 기능은 스케줄, API 워크플로우, GitHub 이벤트 같은 trigger surface를 받는다. 즉 cron 같은 정적 자동화와 닮아 있지만, 실행 시점 맥락에 따라 LLM이 분기 판단을 할 수 있다는 점에서 성격이 다르다.
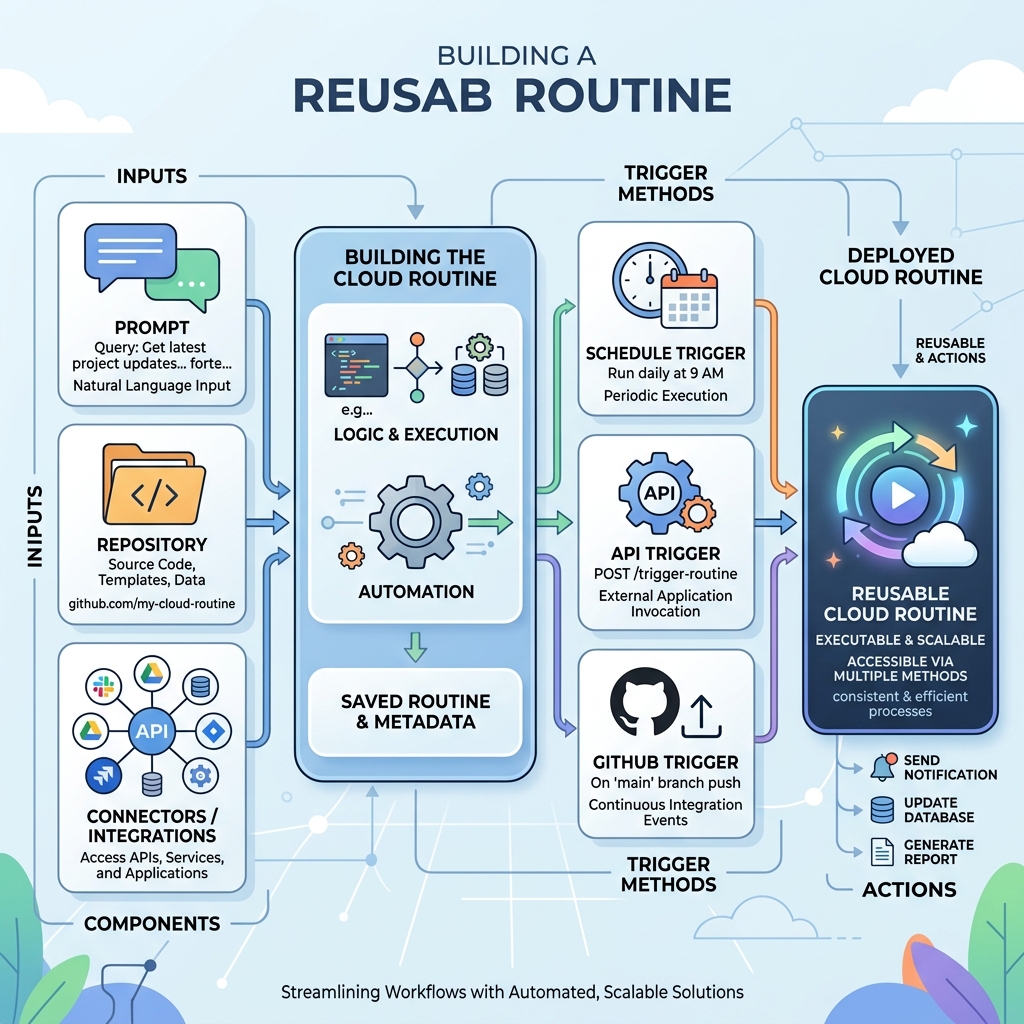
그래서 이 변화를 한 줄로 줄이면 이렇다.
AI 코딩이 아니라 AI 루틴 운영의 시작이다.
왜 이건 cron job보다 더 흥미롭고, 더 까다로운가
많은 개발자가 바로 떠올릴 비교 대상은 cron, GitHub Actions, Zapier 같은 익숙한 자동화다. 나도 그 비교가 가장 실용적이라고 본다.
공통점은 분명하다.
- 정해진 시간에 실행할 수 있다
- 특정 이벤트로 트리거할 수 있다
- 반복 업무를 사람이 직접 열지 않아도 된다
그런데 차이는 꽤 크다.
cron / GitHub Actions→ 정해진 스크립트를 정해진 조건에서 실행→ 결과 경로가 상대적으로 예측 가능
Claude Code Routines→ 저장된 프롬프트와 컨텍스트를 트리거로 실행→ 실행 시점 맥락에 따라 판단과 분기가 달라질 수 있음이 차이가 왜 중요하냐면, 정적 자동화는 덜 유연하지만 디버깅이 쉽다. 반대로 루틴형 자동화는 더 유연하지만, 왜 그렇게 판단했는지까지 같이 봐야 해서 운영 난도가 올라간다.
예를 들어 배포 검증 루틴을 만든다고 해보자.
routine: deployment-checktrigger: type: schedule cron: "0 9 * * 1-5"context: repo: my-service connectors: - github - slackprompt: | CI/CD 로그를 읽고 실패 여부를 요약해줘. 오류가 있으면 원인 후보 세 가지와 재현 가능성을 같이 정리해. 배포 진행 가능 여부를 한 줄로 결론내려.이건 단순히 스크립트를 돌리는 게 아니다. 로그 해석, 중요도 판단, 요약 방식까지 모델이 맡는다. 그래서 생산성은 좋아질 수 있지만, 동시에 “판단 오류를 어디서 잡을 것인가”라는 새 문제가 생긴다.
진짜 핵심은 기능보다 실행층이다
이번 기능에서 내가 제일 크게 보는 포인트는 UI가 아니라 실행층이다. 좋은 프롬프트를 저장하는 기능은 이미 여러 제품이 해왔다. 그런데 Anthropic 인프라 위에서 반복 실행하고, 로컬 머신 상태와 분리했다는 건 전혀 다른 얘기다.
노트북이 꺼져 있어도 돌아간다는 말은, 이제 자동화의 기준점이 개인 컴퓨터가 아니라 공급자 실행층으로 올라갔다는 뜻이다. 이건 다음 질문으로 바로 이어진다.
- 내 루틴은 어디서 실행되나
- 어떤 리포와 커넥터에 접근하나
- 실패 로그와 실행 기록은 얼마나 잘 남나
- 권한 경계는 누가 보장하나
즉 앞으로의 경쟁은 단지 “좋은 모델”이 아니라,
- 반복 실행을 얼마나 쉽게 만들고
- permission boundary를 얼마나 명확히 두고
- 로그와 증적을 얼마나 잘 보여주고
- 오작동을 얼마나 안전하게 제한하느냐
이 네 가지로 갈 가능성이 크다.
같은 날 Google이 Chrome에 Skills를 넣은 것도 방향성을 더 분명하게 만든다. 이름은 다르지만 구조는 비슷하다. 반복 프롬프트를 원클릭 재사용 가능한 workflow asset으로 끌어올리는 흐름이다. 공급자는 다르지만 시장 방향은 하나다.
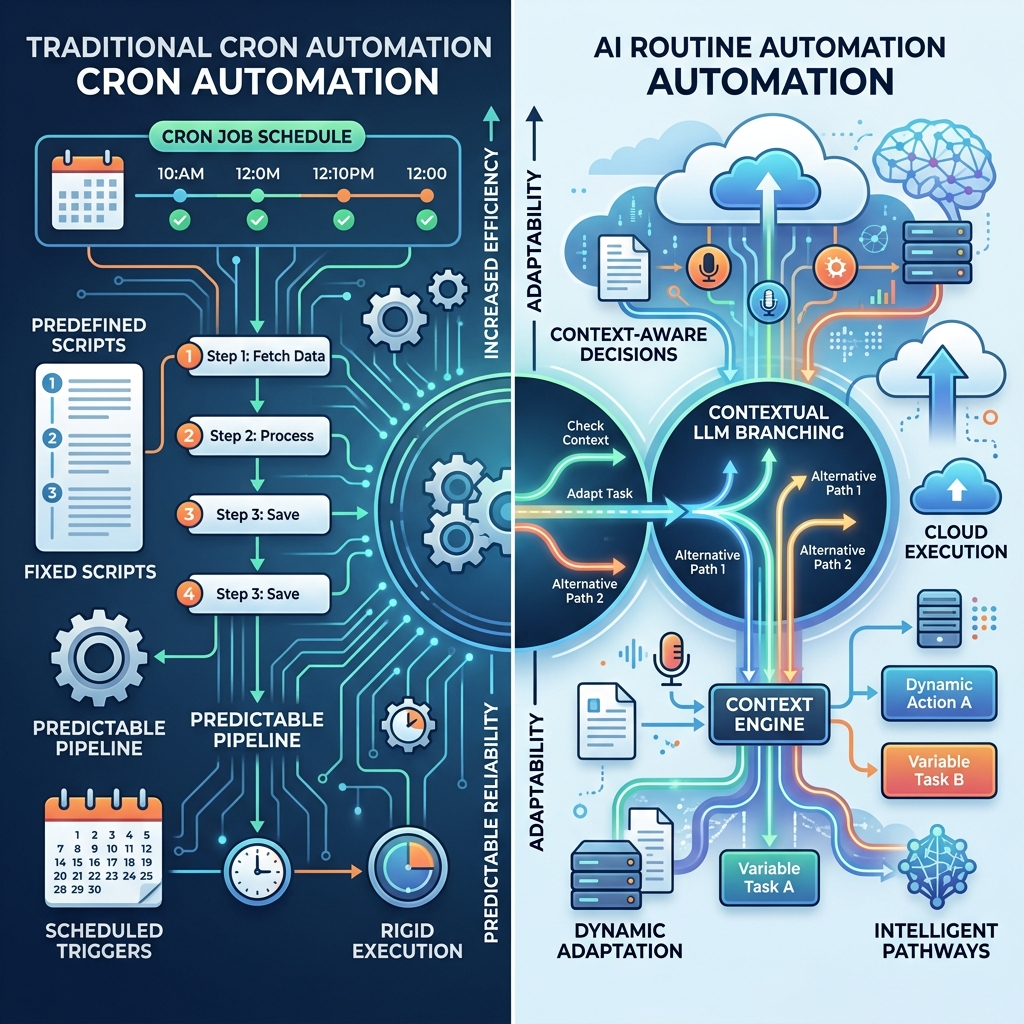
나는 이걸 이렇게 해석한다.
프롬프트는 이제 입력이 아니라 자산이 되고 있다. 그리고 그 자산의 가치 대부분은 모델 품질보다 실행 경계와 재사용성에서 나온다.
아직은 실험 단계인 이유도 분명하다
과열된 반응과 별개로, 지금 당장 모든 운영 자동화를 얹기엔 아직 경계가 있다.
가장 명확한 건 사용량 제한이다. 공개된 안내 기준으로 research preview 단계에서 Pro는 하루 다섯 회, Max는 열다섯 회, Team/Enterprise는 스물다섯 회 제한이 있다. 추가 사용은 조건에 따라 과금 초과 사용으로 갈 수 있다. 이 숫자는 지금 시점 Routines가 “미션 크리티컬 메인 운영선”이라기보다, 고효율 루틴을 선별하고 검증하는 단계에 더 가깝다는 뜻이다.
또 하나는 디버깅 복잡도다. 정적 파이프라인은 실패 원인을 스텝 단위로 자르기 쉽지만, 루틴은 모델 판단이 섞이는 순간 재현성이 떨어질 수 있다. 같은 입력처럼 보여도 연결된 컨텍스트나 외부 상태에 따라 결과가 흔들릴 수 있어서다.
그래서 당장 실무에선 이런 식으로 접근하는 게 맞다.
- 자주 반복되지만 실패 비용이 낮은 업무부터 붙이기
- 요약, triage, 보고서 초안처럼 사람 검토가 남는 업무부터 시작하기
- 배포 승인, 계정 변경, 외부 발송처럼 위험한 액션은 단계적 승인 두기
- 실행 로그와 결과 샘플을 모아, 루틴 품질을 먼저 측정하기
이건 기대를 깎는 얘기가 아니라, 오히려 건강한 운영 관점이다. 루틴의 본질은 “무조건 자동화”가 아니라 반복 의사결정의 비용을 낮추는 것이기 때문이다.
한국 개발자에게 실질적으로 중요한 이유
한국 개발자 커뮤니티에서 Claude Code 실전 글이 빠르게 퍼지는 흐름을 보면, 다음 관심사는 거의 정해져 있다. “어떻게 잘 쓰나” 다음은 “어떻게 반복되게 돌리나”다.
특히 바로 연결되는 실무 케이스가 많다.
1. 코드 리뷰 전처리
PR 열릴 때 변경 범위를 읽고, 위험 파일, 테스트 누락, 리뷰 포인트를 먼저 정리하게 할 수 있다.
2. 운영 알림 triage
슬랙이나 GitHub 이슈로 들어온 장애 알림을 읽고, 중복 여부와 우선순위를 분류하는 루틴으로 쓸 수 있다.
3. 배포 후 요약 리포트
CI/CD 출력과 릴리즈 노트를 함께 읽고, “오늘 배포에서 달라진 점”을 정리하게 할 수 있다.
4. 문서 동기화 루틴
특정 저장소 변경이 생기면 changelog, internal docs, onboarding 문서를 점검하는 식으로 확장할 수 있다.
실무 체크리스트로 줄이면 이렇다.
# 루틴 도입 전 체크1. 사람이 매일 반복하는 텍스트성 업무인가?2. 실패해도 즉시 치명적이지 않은가?3. 결과를 사람이 한 번 더 검토할 수 있는가?4. 접근 권한과 로그가 분리돼 있는가?5. 실행 횟수 제한 안에서 ROI가 나오는가?
내가 보기엔 한국 개발자에게 가장 큰 포인트는 이거다. 이제 좋은 프롬프트를 많이 아는 사람보다, 반복 업무를 잘 정의하고 안전하게 실행층에 올리는 사람이 더 강해질 가능성이 크다.
결론: 경쟁축은 모델에서 루틴 실행층으로 이동 중이다
Claude Code Routines가 던진 메시지는 꽤 명확하다. 이제 AI 도구의 차별점은 단일 응답 품질만이 아니다.
- 프롬프트를 재사용 가능한 작업 자산으로 만들 수 있는가
- 그 자산을 클라우드 실행층에서 반복 호출할 수 있는가
- schedule, API, GitHub 트리거 같은 실제 개발 흐름에 붙일 수 있는가
- 실패 비용을 관리할 로그, 권한, 검토 경계를 제공하는가
이게 지금 경쟁의 새 기준이 되고 있다.
그래서 한 줄 결론은 이거다.
지금 화제의 본질은 “어떤 모델이 더 똑똑한가”가 아니라, 반복 업무를 누구의 실행층 위에서 얼마나 안정적으로 자동화할 수 있나로 경쟁축이 이동했다는 점이다.
참고 소스
- Hacker News,
Claude Code Routinesdiscussion (2026-04-15 17:00 KST 기준) - The Register, “Claude Code routines promise mildly clever cron jobs”
- 9to5Mac, “Anthropic adds routines to redesigned Claude Code, here’s how it works”
- Google Chrome Blog, “Turn your best AI prompts into one-click tools in Chrome”
- Velog, Claude Code 한국어 실전 가이드