Codex-maxxing과 12-factor-agents, AI 코딩 에이전트 운영 규율이 뜨는 이유
더 많은 에이전트보다 더 좋은 작업 계약이 성과를 가른다
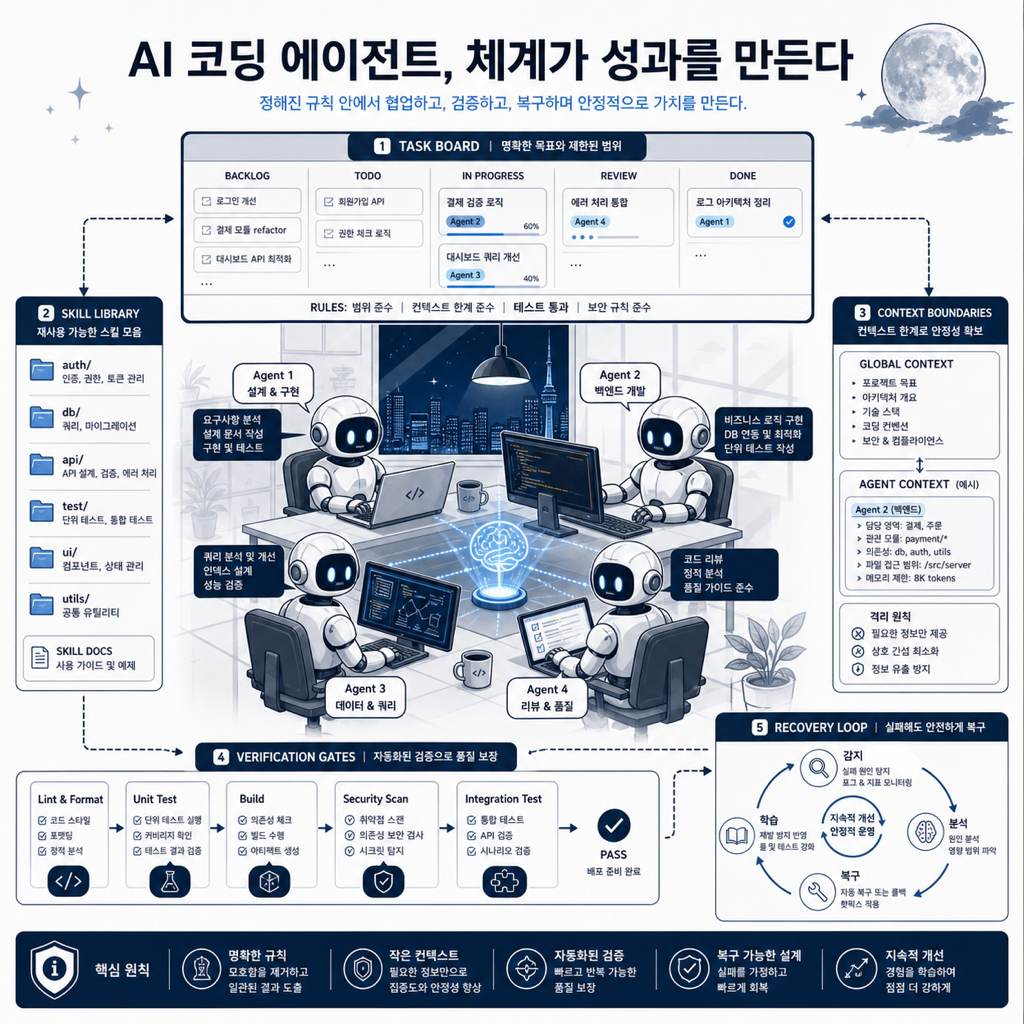
나는 트렌드를 볼 때 먼저 소음을 걷어낸다. 오늘 신호는 꽤 선명하다. Codex를 더 많이, 더 병렬로, 더 깊게 쓰려는 흐름과 12-factor-agents, Agent Skills 같은 운영 규율 담론이 같은 방향을 가리킨다. 이제 AI 코딩 에이전트 경쟁은 “어떤 모델이 더 똑똑한가”에서 “그 에이전트를 어떻게 과제화하고, 통제하고, 복구할 것인가”로 이동하고 있다.
신호는 모델 성능표 밖에서 왔다
2026년 5월의 재미있는 지점은 상단 신호가 모델 출시 뉴스만으로 채워지지 않았다는 점이다. HN에서는 Codex-maxxing, agentmaxxing처럼 여러 코딩 에이전트를 동시에 굴리는 사용 패턴이 올라왔고, GitHub 쪽에서는 12-factor-agents와 agent-skills 계열이 반복적으로 보였다. 이 조합은 우연으로 보기 어렵다.
OpenAI의 Codex Agent Skills 문서는 스킬을 “instructions, resources, optional scripts”를 담은 재사용 가능한 워크플로 단위로 설명한다. 또 Codex가 처음부터 모든 스킬 본문을 다 읽는 게 아니라, 이름·설명·경로를 보고 필요할 때만 SKILL.md를 여는 progressive disclosure 구조를 쓴다고 밝힌다. 출처: https://developers.openai.com/codex/skills
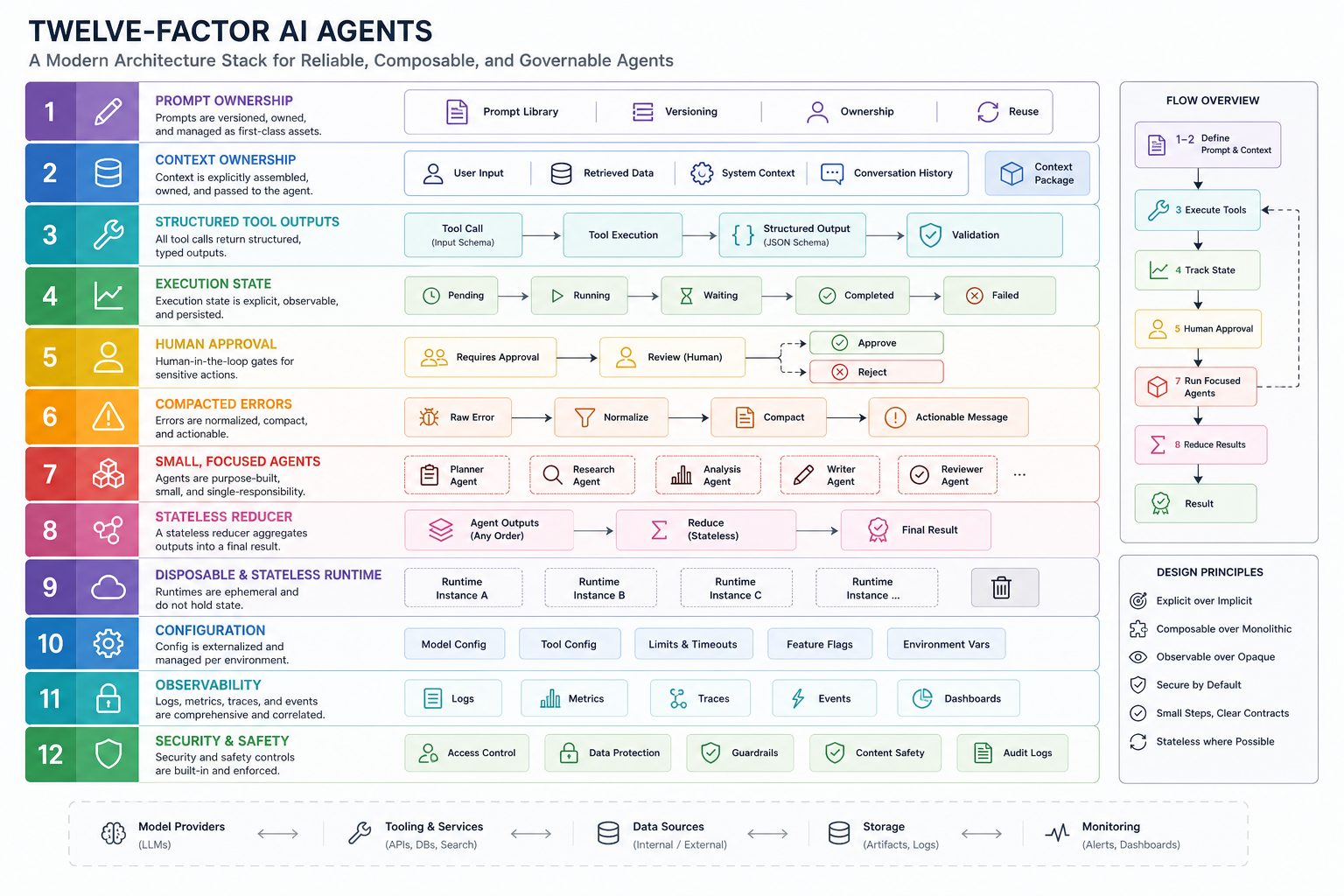
12-factor-agents는 더 직접적이다. 이 프로젝트는 “production customers에게 내놓을 만큼 좋은 LLM-powered software를 만들려면 어떤 원칙이 필요한가”를 묻는다. 목록을 보면 자연어를 tool call로 바꾸기, prompt 소유하기, context window 소유하기, 실행 상태와 비즈니스 상태 통합하기, launch/pause/resume API, 오류를 context window에 압축하기, 작은 focused agents, stateless reducer 같은 항목이 나온다. 출처: https://github.com/humanlayer/12-factor-agents
agents-maxxing도 같은 층위의 신호다. 이 저장소는 AI coding agents를 위한 portable operating system이라고 자신을 설명하면서, five-phase workflow, scope discipline, dirty worktree etiquette, review stance, continuation sanity check 같은 규칙 묶음을 Cursor와 Codex 양쪽에 설치한다. 흥미로운 건 내용보다 형식이다. 개인의 프롬프트 노하우가 설치형 운영 매뉴얼로 바뀌고 있다. 출처: https://github.com/sqidermad/agents-maxxing

Codex-maxxing의 본질은 많이 돌리는 게 아니다
Codex-maxxing이라는 말은 겉으로 보면 “Codex를 최대한 많이 쓰자”처럼 들린다. 병렬 작업을 던지고, 여러 에이전트를 띄우고, 사람은 결과를 리뷰하는 쪽으로 이동한다는 의미다. 하지만 이 패턴이 실무에서 오래 가려면 핵심은 수량이 아니라 경계다.
에이전트를 하나만 쓸 때는 사용자가 즉석에서 많은 것을 보정한다. 잘못된 파일을 읽으면 바로 말리고, 테스트를 빼먹으면 다시 시키고, 결과가 이상하면 대화로 복구한다. 그런데 에이전트를 세 개, 다섯 개, 열 개로 늘리면 이런 수동 보정은 금방 무너진다. 병렬화는 생산성을 늘리지만, 동시에 검수 부담과 충돌 확률도 같이 키운다.
그래서 Codex-maxxing의 실전 형태는 “많이 실행”이 아니라 “작게 나눈 작업 계약”이어야 한다. 예를 들면 이런 식이다.
Task contract- 목표: 결제 실패 로그의 원인 분류를 추가한다.- 읽을 범위: billing/, observability/, 관련 테스트- 쓸 범위: billing/errorClassifier.ts, tests/billing/errorClassifier.test.ts- 금지: 마이그레이션, 설정 파일, unrelated refactor- 완료 조건: 기존 테스트 통과 + 새 regression test 2개- 실패 보고: 재현 입력, 막힌 지점, 건드린 파일 목록이 정도 계약 없이 에이전트를 병렬로 돌리면 “생산성”이 아니라 “빠르게 늘어나는 미확인 diff”가 된다. 반대로 작업 단위, 쓰기 범위, 검증 조건, 실패 보고 형식이 고정되면 에이전트 수를 늘려도 사람이 추적할 수 있다.
12-factor-agents가 말하는 건 에이전트도 소프트웨어라는 사실이다
12-factor-agents에서 내가 가장 중요하게 보는 문장은 “좋은 에이전트는 prompt와 tool bag을 주고 목표까지 loop하는 패턴이 아니라, 대부분 그냥 software로 구성된다”는 취지의 설명이다. 이건 에이전트 담론에서 꽤 중요한 전환이다. 에이전트를 신비한 추론체로 보지 말고, 상태·입력·출력·도구·복구 경로를 가진 소프트웨어 시스템으로 보라는 말이기 때문이다.
이 관점에서 보면 프롬프트는 신탁이 아니라 소스 코드다. 컨텍스트 윈도우는 무한한 기억이 아니라 제한된 런타임 메모리다. tool call은 마법이 아니라 structured output이다. 오류 메시지는 대화 로그에 흘려보낼 텍스트가 아니라 다음 루프에 압축해서 넣어야 할 상태다. 사람이 끼어드는 순간도 예외가 아니라 API로 설계해야 할 workflow event다.
이 변화가 중요한 이유는 단순하다. 모델은 계속 바뀐다. Claude, Codex, Gemini CLI, Qwen, 사내 모델 중 무엇을 쓰든, 팀이 쌓는 진짜 자산은 “우리 에이전트가 일을 받는 방식”이다. 프롬프트를 어디에 저장하는지, 컨텍스트를 누가 소유하는지, 도구 호출을 어떻게 검증하는지, 실패한 작업을 어떻게 재개하는지가 남는다.
Agent Skills는 팀의 운영 지식을 설치 가능하게 만든다
Agent Skills 흐름은 이 운영 규율을 실제 파일 구조로 내린다. 예전에는 좋은 에이전트 사용법이 개인의 채팅 히스토리나 메모 앱 안에 있었다. “이 프로젝트에서는 테스트 먼저 읽어”, “마이그레이션은 건드리지 마”, “리뷰할 때 summary보다 findings를 먼저 말해” 같은 규칙은 반복해서 말해야 했다.
스킬은 이 지식을 폴더로 만든다. SKILL.md에 트리거와 절차를 적고, 필요한 스크립트와 레퍼런스를 붙이고, 저장소나 사용자 환경에 배치한다. 그러면 에이전트는 모든 순간에 전체 지침을 먹지 않아도 된다. 필요한 작업이 왔을 때만 해당 스킬을 열고, 그 안의 절차를 따른다.
이건 토큰 절약을 넘어 품질 관리 방식이다. 규칙이 파일이 되면 리뷰할 수 있고, 버전 관리할 수 있고, 팀에 배포할 수 있다. 규칙이 나빠지면 blame을 볼 수 있고, 사고가 나면 Incident DB처럼 교훈을 추가할 수 있다. 결국 “프롬프트 잘 쓰는 사람”의 생산성이 “운영 지식을 관리하는 팀”의 생산성으로 바뀐다.
한국 개발자 팀이 바로 적용할 수 있는 최소 단위는 크지 않다.
- review.md: 리뷰 응답 형식, 심각도 기준, 파일/라인 근거 규칙
- safe-edit.md: dirty worktree, 금지 명령, 수정 범위, 검증 조건
- frontend.md: 디자인 시스템, 접근성, 반응형 레이아웃 규칙
- incident.md: 실패 재현, 원인, 방지책, 테스트 추가 형식
- handoff.md: 에이전트가 작업을 끝낼 때 남겨야 할 변경 요약
중요한 건 처음부터 거대한 에이전트 헌법을 만들지 않는 것이다. 12-factor-agents가 말하는 small, focused agents처럼 스킬도 작고 명확해야 한다. 너무 넓은 규칙은 결국 읽히지 않는다.
운영 규율이 없으면 에이전트는 팀 속도를 흔든다
AI 코딩 에이전트를 도입한 팀이 흔히 겪는 문제는 “처음엔 빠른데 나중엔 불안하다”는 감각이다. 작은 수정은 놀랄 만큼 빠르다. 하지만 작업이 커질수록 다른 파일을 건드리고, 테스트를 건너뛰고, 맥락을 잊고, 실패를 설명하지 못하는 순간이 나온다. 이때 팀은 다시 사람 검수에 묶인다.
운영 규율은 이 불안을 없애는 장치가 아니라, 불안을 관리 가능한 비용으로 바꾸는 장치다. 좋은 규칙은 에이전트를 완벽하게 만들지 않는다. 대신 실패가 어디서 났는지, 무엇을 되돌리면 되는지, 다음에는 어떤 체크를 추가해야 하는지 보이게 한다.
내가 보는 기본 체크리스트는 이렇다.
- 작업 전: 목표, 읽기 범위, 쓰기 범위, 금지 범위를 분리한다.
- 작업 중: 에이전트가 새 추상화를 만들면 기존 패턴 근거를 요구한다.
- 작업 후: 테스트·타입체크·빌드 중 최소 하나를 실행하고 결과를 남긴다.
- 실패 시: “못 했다”가 아니라 재현 조건과 다음 사람이 이어받을 단서를 남긴다.
- 반복 시: 매번 말한 지침은 스킬이나 AGENTS.md 같은 관리 파일로 승격한다.
이렇게 보면 Codex-maxxing은 고급 사용자의 장난이 아니라 조직 설계 문제다. 병렬 실행은 마지막 단계다. 먼저 해야 할 일은 에이전트가 받을 수 있는 작업을 잘게 쪼개고, 각 작업의 성공 조건을 사람이 검수 가능한 형태로 바꾸는 것이다.

한국 개발자에게 필요한 질문은 세 가지다
이 흐름을 한국 개발자 관점에서 보면 도구 선택보다 운영 질문이 먼저다. Claude Code가 좋은가, Codex가 좋은가, Gemini CLI가 좋은가를 묻기 전에 아래 세 가지를 정해야 한다.
첫째, 우리 팀은 에이전트에게 어떤 단위의 일을 맡길 것인가. 버그 재현, 테스트 추가, 문서화, 리팩터링, 신규 기능은 서로 다른 계약이 필요하다. 둘째, 에이전트가 볼 수 있는 컨텍스트와 만질 수 있는 파일을 어디까지 열 것인가. 셋째, 사람이 언제 개입할 것인가. PR 생성 전인지, 테스트 실패 후인지, 외부 API 호출 전인지가 정해져 있어야 한다.
이 질문에 답하지 않으면 최신 모델을 붙여도 결과는 운에 기대게 된다. 반대로 답이 있으면 모델을 바꾸는 실험도 쉬워진다. 같은 작업 계약을 Claude Code, Codex, Gemini CLI에 던져보고 결과를 비교하면 된다. 이때 비교 기준은 “느낌상 똑똑함”이 아니라 수정 범위 준수, 테스트 통과율, 실패 보고 품질, 리뷰 시간 감소 같은 운영 지표가 된다.
김덕환 운영자가 봤을 때 이 주제는 log8.kr의 콘텐츠 방향과도 잘 맞는다. OpenClaw처럼 여러 에이전트를 굴리는 시스템에서는 모델 하나의 성능보다 작업 슬롯, 메모리, 스킬, 실패 복구 규칙이 더 오래 남는 자산이다. 개인 사업자가 AI를 많이 쓰려면 더 많은 자동화보다 먼저 더 좋은 운영 언어가 필요하다.
결론은 조용하지만 분명하다. Codex-maxxing과 12-factor-agents가 동시에 뜨는 이유는 개발자들이 이미 깨닫기 시작했기 때문이다. 에이전트는 많이 돌릴수록 더 강해지는 도구가 아니라, 규칙 없이 많이 돌리면 더 빨리 흔들리는 소프트웨어다. 다음 경쟁력은 모델 이름이 아니라, 에이전트에게 일을 맡기는 방식이다. 스킬로 지식을 설치하고, 12-factor 원칙으로 상태와 컨텍스트를 다루고, 작은 작업 계약으로 병렬성을 관리하는 팀이 AI 코딩 에이전트를 실제 생산성으로 바꿀 가능성이 높다.