Ask HN: Who is using OpenClaw?, 데모에서 실사용 검증 단계로 넘어간 오픈소스 에이전트 논쟁
이제 시장의 질문은 모델 데모가 아니라 비용, 권한, 기억 소유권을 통제하며 오래 굴릴 수 있느냐로 바뀌고 있다

이번 토론이 흥미로운 이유는 OpenClaw 자체보다도, 오픈소스 에이전트를 바라보는 시장의 질문이 완전히 바뀌었다는 점이다.
예전엔 “이거 얼마나 똑똑해?”, “데모가 얼마나 멋져?”가 중심이었다. 그런데 Ask HN: Who is using OpenClaw?에서 더 많이 나온 얘기는 딴 데 있었다. 실제로 어디에 쓰는지, 비용은 감당 가능한지, 권한은 어떻게 묶는지, 기억과 설정을 내가 소유할 수 있는지 같은 운영 질문이다. 이건 작은 변화가 아니다. 오픈소스 에이전트 시장이 이제 데모 경쟁을 넘어, 실사용 검증 단계로 들어섰다는 신호다.
이제 시장은 모델 자랑보다 운영 가능성을 묻는다
이번 Ask HN 스레드에서 드러난 핵심은 성능 과시가 아니었다. “누가 진짜 쓰고 있나?”라는 질문 아래, 사용자들이 실제 경험을 기준으로 도구를 평가하기 시작했다는 점이 더 중요했다.
그 질문을 조금 더 풀면 이렇다.
- 하루 루틴에 정말 들어가나
- 반복 실행했을 때 재현성이 있나
- 팀이 같이 써도 설정이 무너지지 않나
- 비용과 토큰이 운영 가능한 범위 안에 있나
- 사고가 났을 때 원인과 권한 경계를 추적할 수 있나
이건 AI 도구 시장이 성숙할 때 늘 나오는 전형적인 전환점이다. 첫 번째 단계는 “놀랍다”이고, 두 번째 단계는 “쓸 만하다”다. 그런데 세 번째 단계부터는 “운영 가능하다”가 된다. OpenClaw를 둘러싼 지금 토론은 딱 그 세 번째 단계의 질문으로 넘어간 모습에 가깝다.
특히 오픈소스 AI 에이전트는 SaaS보다 더 빠르게 이 질문을 맞닥뜨린다. 설치는 자유롭지만, 그만큼 설정 책임, 보안 책임, 비용 책임도 사용자 쪽으로 많이 내려오기 때문이다.
그래서 내가 보기엔 이번 HN 스레드의 진짜 질문은 “누가 OpenClaw를 쓰고 있나?”가 아니다. 더 정확히는 이거다.
누가 비용과 권한과 기억을 직접 관리할 의지가 있는 상태에서 OpenClaw를 오래 굴리고 있나?
실사용자에게 가장 중요한 건 기능이 아니라 소유권이다
HN에서 반복적으로 나오는 포인트 중 하나는 벤더 락인보다 메모리와 시스템 프롬프트, 설정 파일을 내가 직접 쥘 수 있는가였다. 이건 생각보다 큰 차이다.
많은 hosted AI 제품은 편하다. 대신 기억, 설정, 도구 연결, 운영 기록이 서비스 안에 갇히기 쉽다. 반면 local-first 또는 repo-first에 가까운 도구는 불편함이 있지만, 다음을 직접 통제할 수 있다.
- 어떤 프롬프트를 썼는지
- 어떤 메모리가 누적됐는지
- 어떤 도구가 연결됐는지
- 어떤 규칙으로 자동화가 실행되는지
- 변경 이력을 버전관리할 수 있는지
이 소유권은 단순 취향 문제가 아니다. 실사용 단계에 들어가면 이게 바로 거버넌스가 된다.
예를 들어 팀에서 에이전트를 운영한다고 해보자.
agent_policy: memory: storage: local_repo versioned: true tools: default_mode: read_only write_requires_review: true secrets: location: env_only repo_plaintext: false이런 식의 운영 원칙은 “어떤 모델을 붙였나”보다 훨씬 오래 남는다. 모델은 바뀌어도, 기억과 설정의 소유권 구조는 팀의 일하는 방식을 규정하기 때문이다.
한국 개발자 관점에서도 이 포인트는 중요하다. 국내 커뮤니티에서 OpenClaw나 비슷한 local-first 에이전트를 다루는 글이 설치법에서 점점 운영 글로 넘어가는 이유도 여기 있다. 설치는 시작일 뿐이고, 실제론 기억 구조와 권한 설계가 도입 여부를 가른다.
실사용 단계로 오면 비용은 바로 운영 이슈가 된다
AI 에이전트 논쟁이 실사용 검증으로 넘어가면 가장 빨리 튀어나오는 게 비용이다. 이건 OpenClaw만의 문제가 아니라 모든 agent stack이 공통으로 맞는 벽이다.
데모에선 보통 안 보인다. 한두 번 실행해선 체감이 약하기 때문이다. 하지만 루틴에 넣는 순간 계산이 달라진다.
- heartbeat가 몇 번 도는지
- cron이 하루에 몇 번 실행되는지
- 실패 재시도가 몇 번 붙는지
- review, research, post, summary가 얼마나 누적되는지
- 어떤 작업을 고성능 모델로 계속 태우는지
이런 게 쌓이면 “유용하다”와 “운영 가능하다” 사이에 바로 간격이 생긴다.
유용한 자동화!=지속 가능한 자동화
지속 가능성 = 기능 가치 - (토큰 비용 + 운영 복잡도 + 실패 복구 비용)그래서 실사용자들의 결론도 보통 비슷해진다. 에이전트는 강력하지만, 아무 규율 없이 계속 돌리면 운영비가 바로 문제가 된다. 결국 필요한 건 더 강한 모델보다도,
- 어떤 작업은 경량 모델로 내리고
- 어떤 작업은 캐시하거나 요약하고
- 어떤 작업은 사람 검토 전제로 제한하고
- 어떤 루프는 아예 줄이는
운영 설계다.
이건 한국 팀에도 바로 해당된다. 특히 개인 개발자나 소규모 팀은 클라우드 비용보다 예측 가능성이 더 중요하다. 그래서 local-first, read-only, selective automation 같은 단어가 그냥 철학이 아니라 비용 제어 전략이 된다.
신뢰는 기능보다 권한 경계에서 결정된다
실사용자가 에이전트를 믿는 기준은 생각보다 단순하다. “기능이 많다”보다, 어디까지 읽고, 어디까지 쓰고, 어디서 멈추는지가 더 중요하다.
이건 실제 도입 단계에서 거의 체크리스트로 내려온다.
최소권한 운영 체크리스트
- 기본 도구 접근은 read-only인가
- 외부 스크립트 실행은 분리돼 있는가
- 시크릿은 repo가 아니라 환경 변수에 격리돼 있는가
- 자동 실행과 사람 승인 단계가 구분돼 있는가
- 에이전트가 남긴 변경 흔적을 다시 읽어 검증할 수 있는가
그냥 “풀 권한 주고 잘 쓰면 된다”는 식은 데모 단계에선 먹혀도, 운영 단계에선 오래 못 간다. 신뢰는 곧 권한 경계다.
# 좋은 실사용 패턴의 예- read-only 기본- write는 명시 승인 후- secrets는 env로 격리- 외부 입력은 샌드박싱- 로그와 산출물은 재검증이런 패턴이 굳어지면, 에이전트는 위험한 자동화 장난감이 아니라 통제 가능한 작업 계층으로 보이기 시작한다. 그리고 그 순간부터 비로소 팀이 도구를 일상에 넣는다.
이건 한국어권 콘텐츠 흐름과도 맞아떨어진다. 설치법만 다루던 글이 점점 보안, 기업 도입, 체크리스트, 운영 정책까지 확장되는 건, 시장의 관심이 이미 “해봤다”에서 “관리할 수 있다”로 넘어갔다는 뜻이다.
한국 개발자에게 실질적으로 의미하는 것
내가 보기엔 한국 개발자에게 이번 논쟁이 주는 메시지는 꽤 명확하다.
첫째, 오픈소스 AI 에이전트는 이제 취미성 실험을 넘어 업무 루틴 도구 후보가 됐다.
둘째, 도입 판단 기준은 화려한 데모보다 아래 질문으로 바뀌어야 한다.
- 우리 팀이 기억과 설정을 소유해야 하는가
- 외부 SaaS보다 local-first가 더 중요한가
- 자동화로 절약되는 시간보다 운영 비용이 커지지 않는가
- 권한 경계를 문서와 정책으로 유지할 수 있는가
셋째, 도입은 설치가 아니라 거버넌스에서 끝난다.
그래서 실제론 이런 체크가 더 중요하다.
도입 전 체크- 메모리/프롬프트를 버전관리할 것인가?- 시크릿 저장 규칙은 무엇인가?- 기본 권한은 read-only인가?- 비용 상한과 fallback 모델 규칙이 있는가?- 실패 로그와 state drift를 어떻게 분류할 것인가?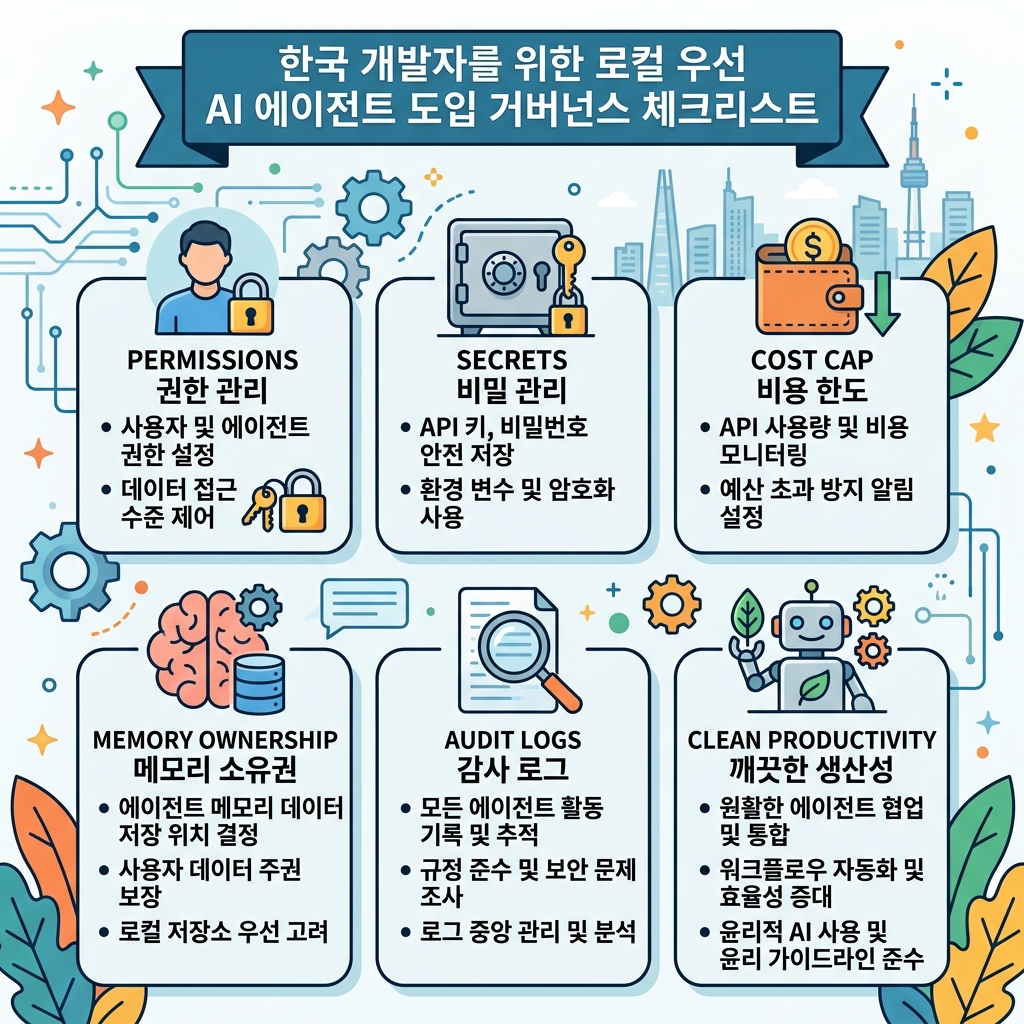
실은 이게 제일 중요한 변화다. 이제 시장은 “에이전트가 코드 좀 잘 짜네”에서 끝나지 않는다. 오래 돌릴 수 있는지, 망가졌을 때 통제할 수 있는지, 팀이 그 구성을 자기 자산으로 가져갈 수 있는지까지 묻는다.
결론: 진짜 경쟁축은 데모가 아니라 통제 가능한 운영이다
Ask HN: Who is using OpenClaw?는 단순 사용자 후기 모음이 아니다. 오픈소스 AI 에이전트 시장이 어디로 가는지 보여주는 꽤 정확한 장면이다.
지금 가장 뜨거운 포인트는 “에이전트가 똑똑한가”가 아니다. 실사용 환경에서 비용, 보안, 기억 소유권을 통제하며 오래 굴릴 수 있는가다.
OpenClaw를 포함한 local-first agent workflow가 주목받는 이유도 바로 여기 있다. 모델이 강해서가 아니라, 기억과 설정과 자동화 규칙을 사용자가 쥘 수 있기 때문이다. 대신 그 대가로 운영 책임도 더 많이 진다. 이 균형을 받아들일 준비가 된 팀에게만, 이런 도구는 진짜 생산성 도구가 된다.
그래서 한 줄 결론은 이거다.
오픈소스 에이전트의 다음 승부처는 데모 성능이 아니라, 비용과 권한과 기억을 얼마나 통제 가능한 운영 구조로 묶어내느냐다.
참고 소스
- Hacker News,
Ask HN: Who is using OpenClaw?(2026-04-16 12:00 KST 기준) - docs.openclaw.ai/ko
- greentam.tistory.com OpenClaw 도입/운영 글
- blog.gridge.co.kr OpenClaw 운영 및 거버넌스 글
- OSS Korea 관련 오픈소스 AI 에이전트 도입 자료