Rapid-MLX와 26M 툴콜링 모델, 로컬·소형 에이전트가 현실 옵션이 되는 이유
큰 모델 하나를 더 세게 쓰는 시대에서, 작고 가까운 실행 모델을 여러 레이어에 배치하는 시대로 간다
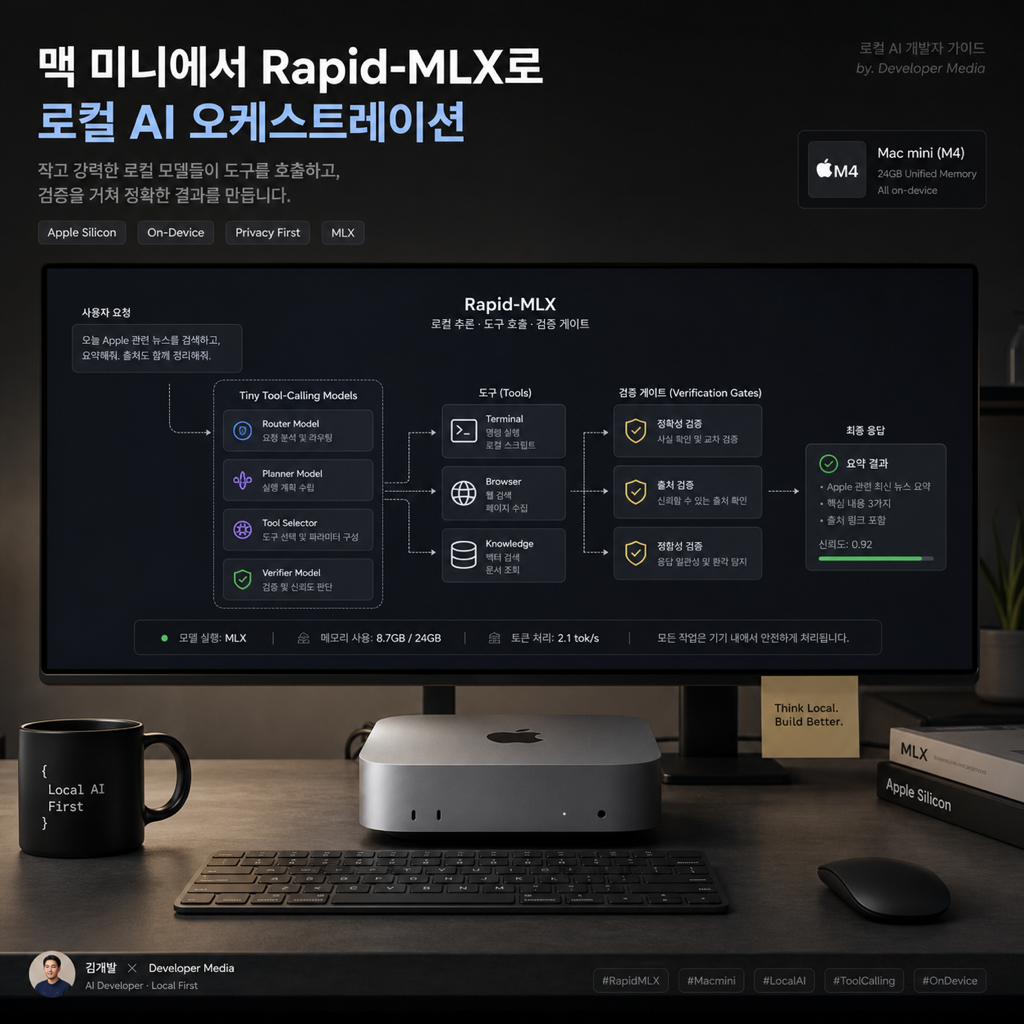
나는 에이전트 장애를 볼 때 모델 이름보다 먼저 로그와 탭 수, 재시도 횟수, 로컬 프로세스를 본다. 그래서 Rapid-MLX와 26M 툴콜링 모델 신호를 그냥 “로컬 AI가 빨라졌다”로 읽지 않는다. 이건 더 큰 모델 하나로 모든 일을 밀어붙이는 구조에서, 작고 가까운 실행 모델을 라우터·검증기·전처리기처럼 배치하는 구조로 넘어가는 신호다.
이번 주 흐름은 꽤 선명했다. 5월 12일 한국 피드에서는 “Rapid-MLX - Apple Silicon 전용 초고속 로컬 AI 엔진”이 강하게 잡혔고, 5월 13일에는 “Needle: We Distilled Gemini Tool Calling into a 26M Model”이 HN 상위권 신호로 올라왔다. 둘을 따로 보면 하나는 Mac 로컬 실행 성능, 하나는 작은 툴콜링 모델이다. 같이 보면 결론이 다르다. 이제 에이전트 운영의 질문은 “가장 똑똑한 모델이 무엇인가”만이 아니라 어떤 작업을 굳이 프런티어 모델까지 보내야 하는가가 된다.
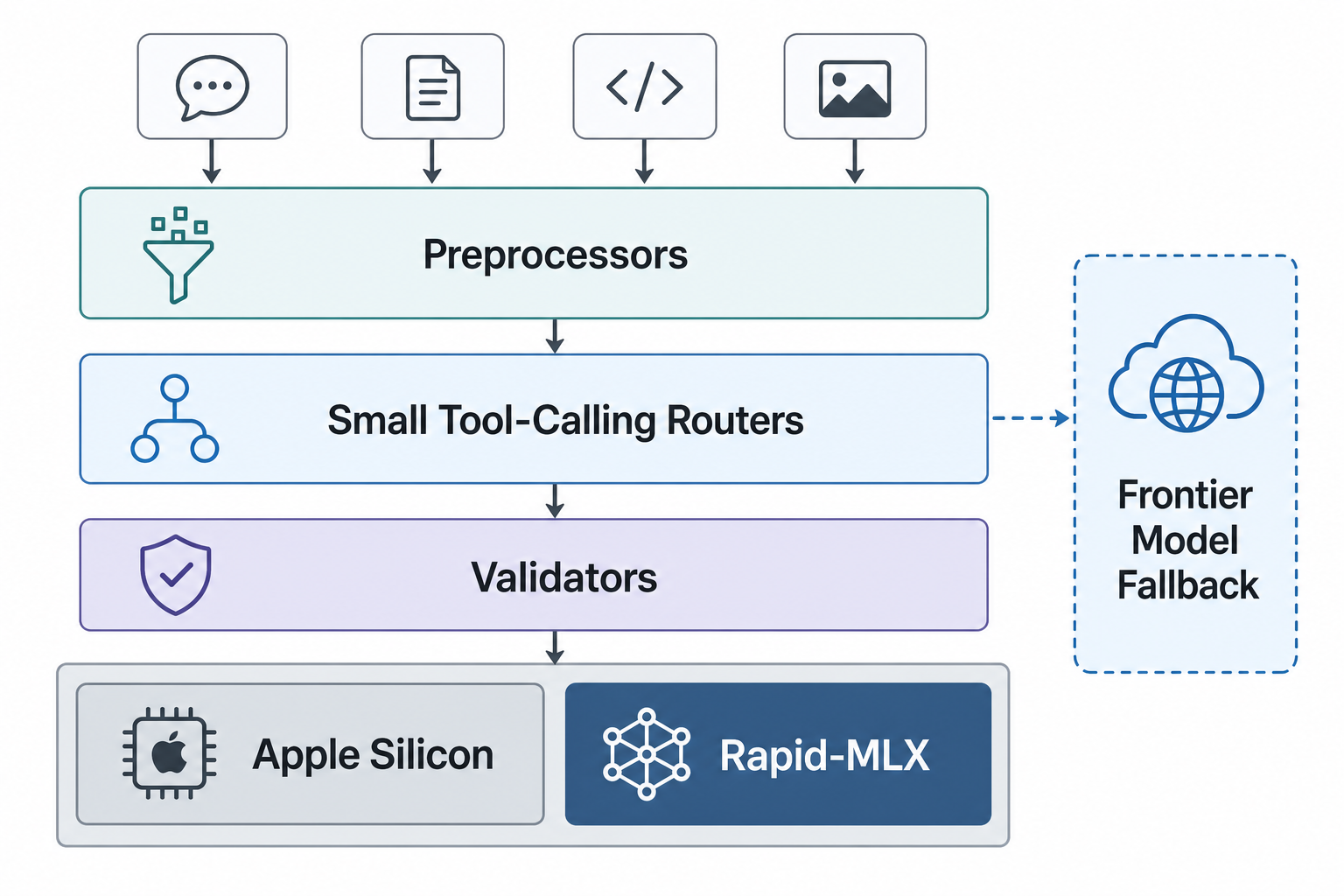
Rapid-MLX의 의미는 빠른 채팅 서버가 아니다
Rapid-MLX는 Apple Silicon에서 로컬 모델을 OpenAI 호환 API처럼 띄우는 쪽에 초점이 있다. 공개 README 기준 메시지는 노골적이다. Mac에서 로컬 AI를 돌리고, Cursor·Claude Code·Aider·OpenClaw 같은 OpenAI 호환 클라이언트에 붙이며, Qwen 계열 같은 모델을 토큰 속도와 툴콜링 파서까지 포함해 실사용 가능한 서버로 만든다는 주장이다.
여기서 중요한 건 “Ollama보다 몇 배 빠르다”는 문구 자체가 아니다. 벤치마크 수치는 환경마다 흔들린다. 내가 보는 핵심은 로컬 실행이 기존 에이전트 하네스에 거의 그대로 꽂힌다는 점이다.
개념은 단순하다.
OPENAI_BASE_URL=http://localhost:8000/v1OPENAI_API_KEY=not-neededMODEL=default이 구조가 되면 로컬 모델은 별도 장난감이 아니다. 기존 코드 에이전트, 브라우저 자동화, 검증 스크립트, 사내 도구 호출 흐름에 바로 들어온다. “내 맥에서 채팅한다”가 아니라 내 워크플로 안쪽에 작은 실행 엔진을 박는다가 된다.
운영 관점에서 이건 세 가지를 바꾼다.
첫째, 지연 시간이 줄어든다. 매번 외부 API까지 왕복하지 않아도 되는 작업이 생긴다. 라우팅, 파일 분류, 간단한 JSON 정리, 로그 triage 같은 작업은 응답 시작 시간이 더 중요할 때가 많다.
둘째, 비용이 예측 가능해진다. 프런티어 모델은 어려운 판단에 남겨두고, 반복 작업은 로컬 엔진이 먹으면 월말 API 청구서가 덜 출렁인다.
셋째, 데이터 경계가 단순해진다. 모든 입력을 외부 모델로 보내지 않아도 된다. 보안팀 입장에서는 이게 꽤 크다. 로그, 경로, 내부 파일명, 실패 스택 같은 민감한 운영 신호를 로컬에서 1차 처리할 수 있다.
26M 툴콜링 모델은 대형 모델 대체재가 아니다
Needle의 26M 툴콜링 모델 신호를 과장하면 안 된다. 26M 모델이 Claude나 GPT급 판단을 대체한다는 말이 아니다. 오히려 반대다. 이 신호의 가치는 작은 모델도 특정 실행 판단 하나는 맡을 수 있다는 데 있다.
툴콜링은 대화 능력과 다르다. 모델이 멋진 설명을 쓰는지보다 다음 질문이 중요하다.
- 지금 도구를 호출해야 하는가
- 어떤 도구를 골라야 하는가
- 인자는 스키마에 맞는가
- 호출 결과를 다시 큰 모델로 보낼 가치가 있는가
- 실패했을 때 같은 호출을 반복하면 위험한가
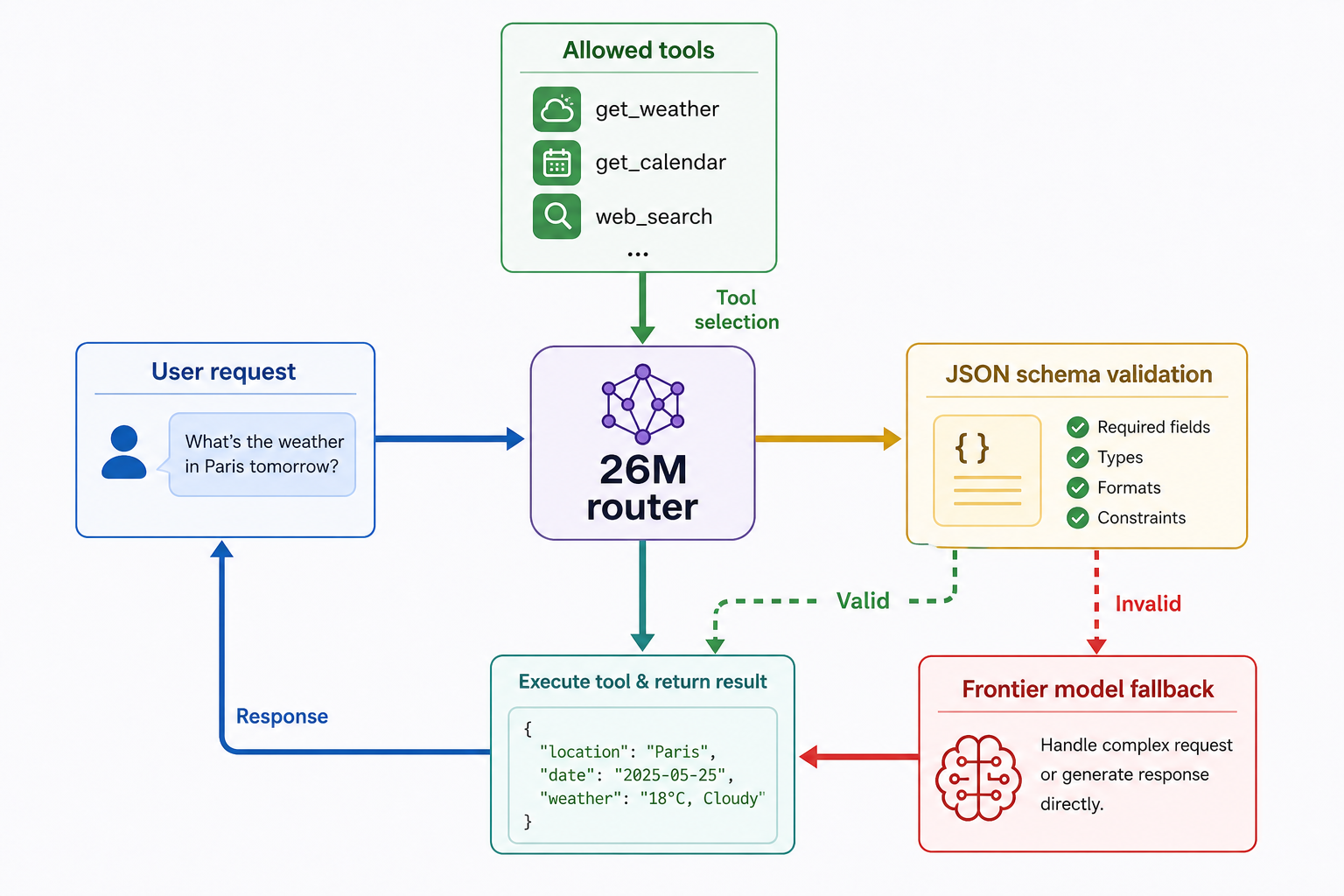
이런 판단은 에이전트 시스템에서 자주 반복된다. 그리고 반복된다는 건 분리할 수 있다는 뜻이다. 큰 모델이 매번 “이 로그를 읽고 어떤 도구를 부를지”까지 다 생각할 필요가 없다. 작은 툴콜링 모델이 1차 라우팅을 맡고, 애매하거나 위험한 케이스만 상위 모델로 올리면 된다.
내가 실제 운영에 배치한다면 이런 식이다.
user/request -> small router: 작업 종류와 위험도 분류 -> small tool caller: 허용된 도구 후보와 인자 생성 -> validator: JSON schema, 권한, rate limit 확인 -> frontier model: 모호한 판단, 긴 컨텍스트, 사용자-facing 답변 -> audit log: 호출 이유와 실패 원인 기록이 설계의 목적은 싸게 때우기가 아니다. 큰 모델이 잘해야 하는 일과 작은 모델이 충분히 잘할 수 있는 일을 분리하는 것이다. 프런티어 모델은 희소한 자원처럼 다뤄야 한다. 모든 이벤트를 다 올리면 비용도 커지고, 장애 면도 넓어진다.
로컬·소형 에이전트가 먼저 들어갈 자리는 하위 레이어다
한국 개발자가 이 흐름을 바로 제품 전체 대체로 보면 실망할 가능성이 높다. 로컬 소형 모델은 아직 긴 추론, 복잡한 설계, 미묘한 제품 판단에서 한계가 있다. 하지만 에이전트 하위 레이어에는 이미 들어갈 자리가 많다.
가장 먼저 볼 곳은 preflight다. 요청이 너무 큰지, 금지 경로를 건드리는지, 필요한 입력이 빠졌는지, 이미 같은 작업이 실행 중인지 검사하는 일이다. 이런 판단은 규칙과 짧은 문맥이면 충분한 경우가 많다.
두 번째는 log triage다. 긴 로그를 다 이해하는 게 아니라, 실패 유형을 auth, rate_limit, timeout, schema, permission, stale_path 정도로 분류하는 일이다. 이건 로컬에서 돌릴수록 좋다. 로그에는 민감한 경로와 내부 구조가 자주 섞인다.
세 번째는 tool argument repair다. 작은 모델이 깨진 JSON을 스키마에 맞춰 고치거나, 허용된 enum으로 맞추거나, 누락 필드를 찾아내는 작업은 꽤 현실적이다. 이 단계에서 검증기는 반드시 코드로 둬야 한다. 모델이 고쳤다고 믿으면 안 된다. 모델은 후보를 만들고, 검증은 결정론적 코드가 한다.
네 번째는 fallback decision이다. 로컬 모델이 “이건 내가 처리하면 위험하다”를 말하게 하는 것도 가치가 있다. 좋은 소형 모델 배치는 모든 걸 처리하는 배치가 아니라, 언제 물러날지 아는 배치다.
출력 계약은 이렇게 좁히는 편이 낫다.
action: handle_locally | escalate | blockreason: 짧은 근거tool: 허용된 도구 이름 또는 없음risk: low | medium | high이런 식의 출력 계약을 두면 작은 모델은 자유 대화자가 아니라 운영 부품이 된다. 그 순간부터 평가도 쉬워진다. “답변이 마음에 드는가”가 아니라 “분류 정확도, 잘못된 호출률, escalation precision, 평균 지연 시간”으로 볼 수 있다.
보안 경계는 더 중요해진다
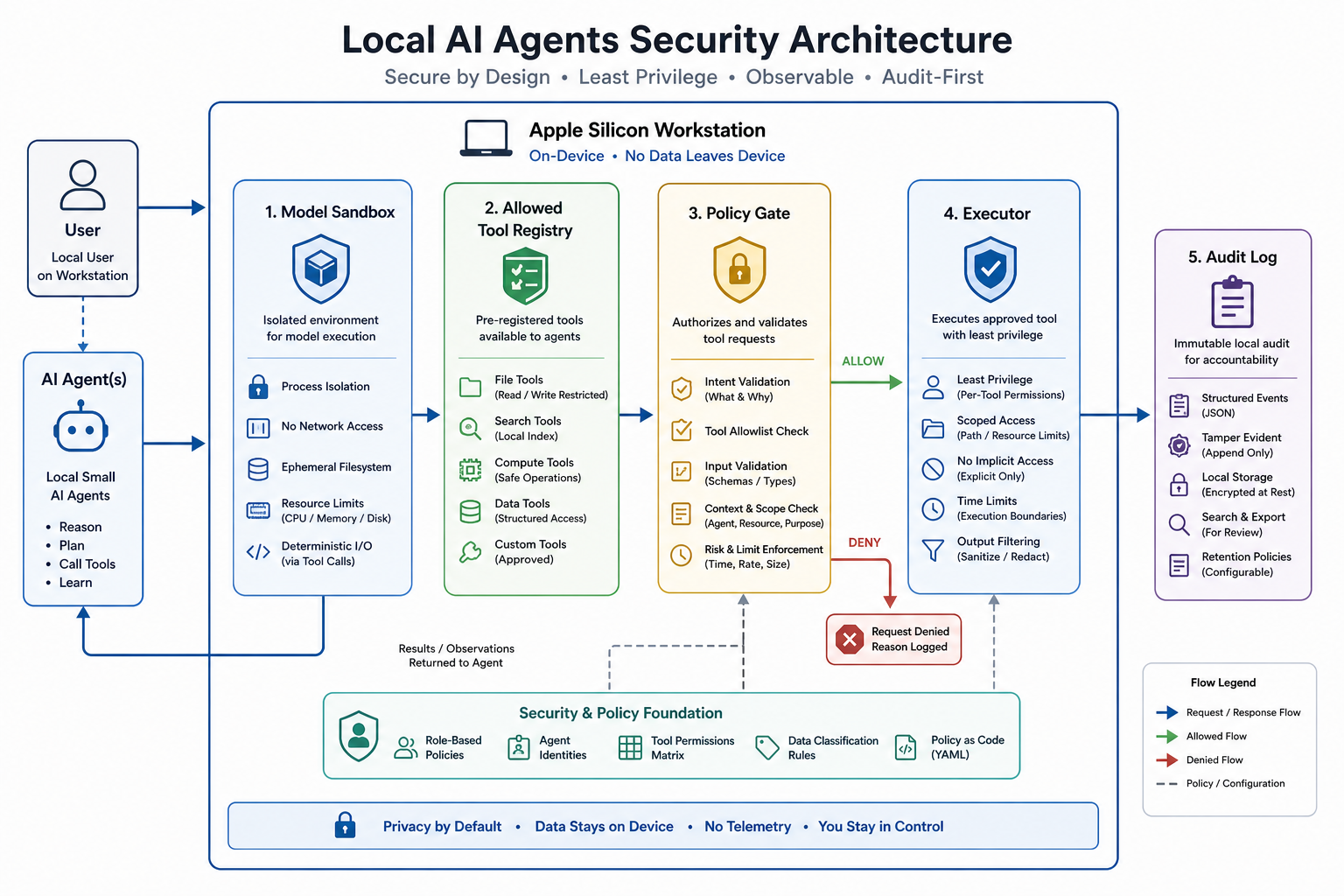
로컬에서 돈다고 안전한 건 아니다. 이건 자주 착각한다. 로컬 모델이 파일시스템과 도구 가까이에 붙을수록, 잘못된 툴콜은 더 빠르게 사고가 된다. 외부 API보다 가까우니까 안전한 게 아니라, 가까우니까 권한 경계가 더 중요하다.
소형 툴콜링 모델을 붙일 때 최소한 이 네 가지는 분리해야 한다.
- 모델이 볼 수 있는 입력
- 모델이 제안할 수 있는 도구
- 실제 실행기가 허용하는 도구
- 실행 뒤 남기는 감사 로그
특히 tool calling은 자연어 답변보다 위험하다. 답변은 사람이 읽고 멈출 수 있지만, 도구 호출은 실행 경로로 이어진다. 그래서 로컬 소형 모델은 절대 “권한 있는 실행자”가 되면 안 된다. 모델은 후보를 낸다. 정책 엔진이 거른다. 실행기는 최소 권한으로 돈다. 결과는 로그로 남는다.
한국 개발자에게 현실적인 도입 순서
지금 당장 모든 에이전트를 로컬로 옮길 필요는 없다. 오히려 그렇게 하면 실패한다. 현실적인 순서는 작게 시작하는 것이다.
1단계는 읽기 전용 분류기다. 로그, 이슈, 문서, 사용자 요청을 분류하고 태그만 붙인다. 실행 권한은 없다. 여기서 지연 시간과 분류 정확도를 본다.
2단계는 도구 호출 후보 생성기다. 실제 실행은 사람이 승인하거나 별도 검증 코드가 통과해야 한다. 이 단계에서는 JSON schema 위반률과 잘못된 도구 선택률을 기록한다.
3단계는 반복 작업의 로컬 처리다. 예를 들어 스크린샷 후 탭 수 검증, 빌드 로그 에러 분류, PR 본문 체크리스트 검증, 중복 콘텐츠 탐지 같은 작업이다. 실패 비용이 작고 검증이 쉬운 작업부터 넣는다.
4단계는 프런티어 모델 절약 레인이다. 작은 모델이 확실히 처리한 건 로컬에서 끝내고, 애매한 건 큰 모델로 올린다. 이때 핵심 KPI는 API 비용 절감률이 아니다. 더 중요한 건 잘못 로컬 처리한 비율이다. 비용을 줄이려고 위험한 케이스를 로컬에 묶어두면 전체 시스템 품질이 떨어진다.
좋은 기준은 이렇다.
local_ok: 입력이 짧다 정책이 명확하다 출력 스키마가 고정돼 있다 실패해도 되돌리기 쉽다 코드 검증으로 잡을 수 있다
escalate: 긴 맥락 판단이 필요하다 사용자 신뢰에 직접 영향을 준다 권한 있는 쓰기 작업이다 보안·과금·삭제 경로가 있다이 기준을 세우면 Rapid-MLX 같은 로컬 엔진과 26M 툴콜링 모델은 유행어가 아니라 운영 선택지가 된다. 큰 모델을 버리는 게 아니라, 큰 모델을 더 귀하게 쓰는 구조다.
결론: 작은 모델은 두뇌가 아니라 실행 근육이다
2026년 로컬 AI 흐름의 핵심은 “이제 내 맥이 GPT를 이긴다”가 아니다. 그런 식으로 쓰면 틀린 글이다. Rapid-MLX가 보여주는 건 Apple Silicon 로컬 실행이 기존 에이전트 도구에 붙을 만큼 가까워졌다는 점이고, 26M 툴콜링 모델 신호가 보여주는 건 작은 모델도 특정 실행 판단을 맡을 수 있다는 점이다.
그러면 아키텍처가 달라진다. 프런티어 모델은 기획자·판단자·복잡한 디버거로 남고, 로컬 소형 모델은 라우터·전처리기·검증 보조·반복 실행자로 내려온다. 이 분업이 잘 되면 비용은 줄고, 지연은 낮아지고, 데이터 경계는 단순해진다. 반대로 권한 경계 없이 붙이면 사고가 더 빨라진다. 로컬이라서 안전한 게 아니라, 로컬이라서 더 엄격히 잘라야 한다.
김덕환 운영자가 봤을 때 이 흐름은 log8.kr 글감 이상의 의미가 있다. OpenClaw처럼 여러 에이전트가 크론, 브라우저, 파일, PR을 만지는 시스템에서는 모든 판단을 큰 모델에게 보내는 구조가 오래 못 간다. 작은 로컬 모델이 preflight와 검증, 로그 분류를 맡고 큰 모델은 진짜 어려운 판단에 남는 쪽이 더 운영자다운 선택이다.
지금 필요한 건 거창한 로컬 AGI 선언이 아니다. localhost에서 빠르게 돌고, 스키마로 묶이고, 실패하면 멈추고, 위험하면 상위 모델로 올리는 작은 실행 모델이다. 그 정도면 충분히 현실적이다. 그리고 그 정도가 실제 운영에서는 제일 먼저 돈값을 한다.
참고 신호
- Rapid-MLX GitHub README: Apple Silicon 로컬 AI 엔진, OpenAI 호환 API, Claude Code·Cursor·Aider·OpenClaw 연결, 툴콜링 파서 지원을 전면에 둔다.
- research-signals-2026-05-12.md: GeekNews에서 Rapid-MLX가 한국 개발자 피드의 강한 로컬 실행 성능 신호로 잡혔다.
- research-signals-2026-05-13.md: “Needle: We Distilled Gemini Tool Calling into a 26M Model”이 HN 상위권 신호로 잡혔다.
- weekly-brief-2026-05-17.md: 로컬·소형·효율형 AI가 취향이 아니라 기본 아키텍처 후보로 올라왔다고 정리했다.